在软件开发过程中,持续集成和持续部署(CI/CD)已经成为不可或缺的一部分。Drone 是一个轻量级、云原生的CI/CD平台。
Drone的优势在于:
- 简单易用,配置直观
- 支持多种Runner(Docker、SSH、Kubernetes等)
- 与Git平台深度集成
- 资源占用少,性能优秀
本文将详细介绍如何从零开始配置一个完整的Drone CI/CD系统,包括处理私有仓库认证等复杂场景。
本文是来自 The University of Manchester 的 John Alistair Kressel 等发表在 ACM SOSP 2025 上的论文。
µFork成功解决了在单地址空间操作系统中支持POSIX fork的长期难题。通过巧妙利用CHERI硬件特性和创新的CoPA优化策略,µFork在保持SASOS轻量化特性的同时,提供了强隔离性和完全的应用兼容性。
Abstract:
Single-address-space operating systems have well-known lightweightness benefits that result from their central design idea: the kernel and applications share a unique address space. This model makes these operating systems (OSes) incompatible by design with a large class of software: multiprocess POSIX applications. Indeed, the semantics of the primitive used to create POSIX processes, fork, are inextricably tied to the existence of multiple address spaces. Prior approaches addressing this issue trade off lightweightness, compatibility and/or isolation. We propose μFork, a single-address-space operating system design supporting POSIX fork on modern hardware without compromising on any of these key objectives. μFork emulates POSIX processes (μprocesses) and achieves fork by creating for the child a copy of the parent μprocess’ memory at a different location within a single address space. This approach presents two challenges: relocating the child’s absolute memory references (pointers), as well as providing user/kernel and μprocesses isolation without impacting lightweightness. We address them using CHERI. We implement μFork and evaluate it upon three real-world use-cases: Redis snapshots, Nginx multi-worker deployments, and Zygote FaaS worker warm-up. μFork outperforms previous work and traditional monolithic OSes on key lightweightness metrics by an order of magnitude, e.g. it can offer a fork-bound FaaS function throughput 24% higher than that of a monolithic OS, and can fork a μprocess in 54 μs, 3.7× faster than a traditional fork.
Entry:Zotero link URL link
无监督学习是机器学习中一个极具挑战性又充满魅力的领域。与监督学习不同,无监督学习处理的是没有标签的数据,其目标是从数据本身发现内在结构、模式或分布。本篇博客将系统介绍无监督学习的核心任务与方法,包括密度估计(直方图法、核密度估计、对比密度学习)、隐变量模型(及其四种类型),并重点剖析自编码器(尤其是主成分分析-PCA)和K-means聚类算法的原理与应用。
监督学习(Supervised Learning)是机器学习的核心范式之一,其目标是从已标注的数据中学习一个映射函数,用于预测未知数据的输出。其核心流程包括:
- 选择归纳偏置(Inductive Bias):模型类、损失函数、正则项;
- 训练:通过ERM或正则化ERM求解参数;
- 验证:使用验证集选择超参数;
- 测试:在独立测试集上评估泛化性能。
本文将系统介绍监督学习的基本概念、方法框架和实际应用,涵盖回归(Regression)与分类(Classification)问题、经验风险最小化(Empirical Risk Minimization, ERM)、模型选择(Model Selection)、偏差-方差权衡(Bias-Variance Tradeoff)、正则化技术(Regularization)以及概率模型中的最大似然估计(Maximum Likelihood Estimation, MLE)等内容。
在现代机器学习应用中,我们经常需要从已知输入变量预测未知的目标变量。本篇博客将深入探讨当数据模型完全已知时的理想 推断(Inference) 场景,介绍贝叶斯推断(Bayesian Inference)、损失函数(Loss Function)、 交叉熵(Cross-Entropy) 等核心概念,以及如何从概率模型推导出最优预测器(Predictor)。通过理论推导和实际例子,我们将展示 硬预测(Hard Prediction) 与 软预测(Soft Prediction) 的区别与联系,以及如何在不同问题中选择合适的预测策略。
继 7 月 16 日 AWS 在 AWS Summit NYC 2025 上发布 Bedrock AgentCore 后,7 月 29 日阿里云在世界人工智能大会上公布了 Agent Runtime 的产品,标志着正式进入和 Agentic Infra 上的产品竞争。
下面分别总结分析 AWS Bedrock AgentCore 和 阿里云无影 AgentBay 的相关发布信息。
NVIDIA Nsight 工具集是面向 CUDA 应用程序的专业级性能分析平台,其 Profiling 模块通过采集 GPU 硬件计数器、内存访问模式及内核执行时序等数据,为深度学习框架的优化提供量化依据。
尽管 Deepspeed 在单机运行时可以直接使用 Nsight 进行分析,但是在多机运行时存在问题,本文讲解:
- 如何跨机进行 profile
- 如何有选择的进行 profile
本论文是来自 Apple 的 Jiarui Lu 2024 年 8 月挂在 Arxiv 上的工作。
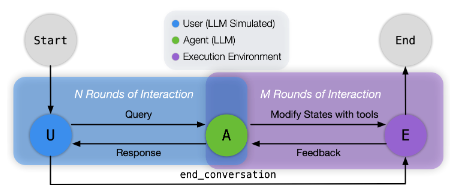
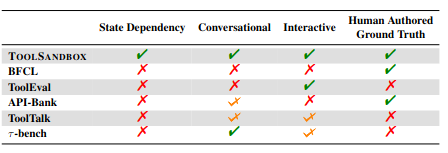
通过引入了对话交互、状态依赖等实际场景的输入,建立了更贴近于真实场景的 LLM Tool Use 的 Benchmark。本文引入了三部分更真实的要点,通过 LLM 模拟用户进行跟真实的测试:
- Stateful 有状态:Agent 需要对世界的状态进行感知
- Conversational 可对话:Agent 能成功把自然语言理解成正确的任务
- Interactive 可交互:用户、Agent和Tool在完成一个任务的过程中会进行多轮对话
Entry:Zotero link URL link Github link
本论文是来自微软的 Chaoyun Zhang 等人在3月11日挂在 Arxiv 上的工作。
本文主要总结了 API Agents 和 GUI Agents 的现状,对比了其优势,提出未来的 Hybrid Agents,最终给出了对于不同场景应该使用什么 Agent 的建议。
Entry:Zotero link URL link
本文主要记录在实验室的 Manjaro 主机上的 i3wm 即工作环境的配置,以及o双显示器的完整工作流内容.
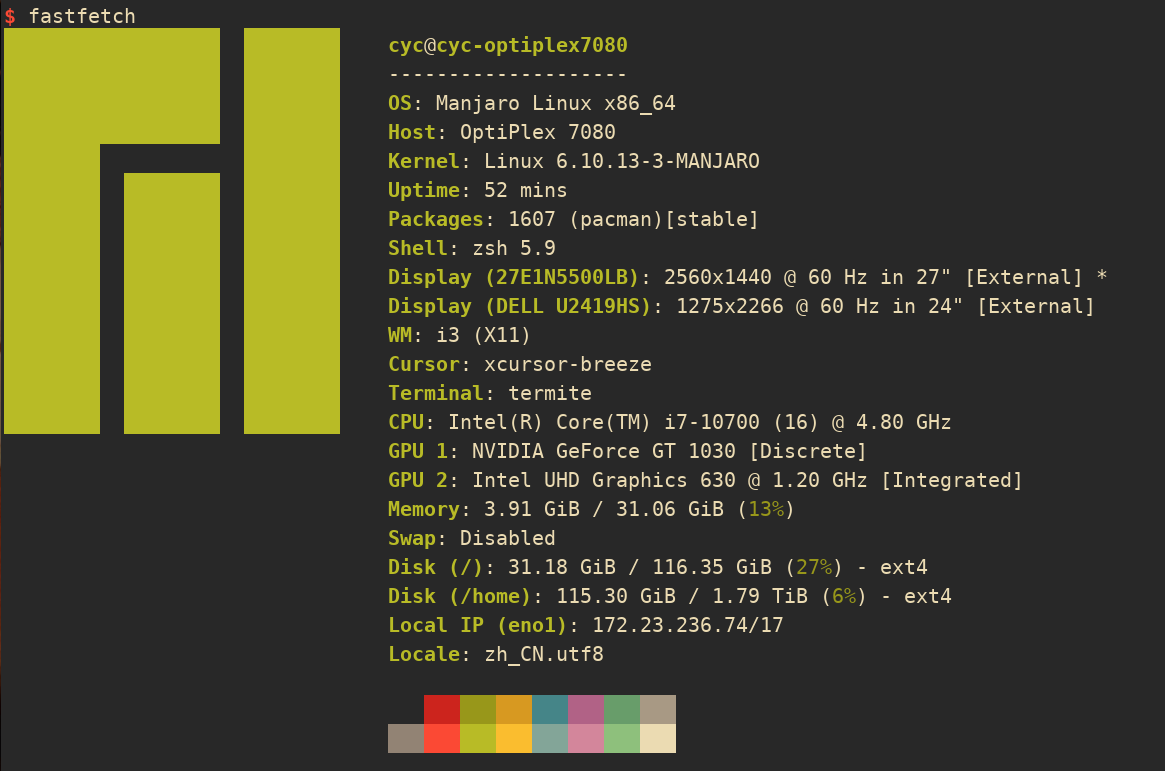
主要内容涵盖:
- 显卡支持
- 显示器布局
- OpenVPN 自动连接
- 通用软件配置