Rina: Enhancing Ring-AllReduce with In-network Aggregation in Distributed Model Training
本论文是 Zixuan Chen, Xuandong Liu, Minglin Li, Yinfan Hu, Hao Mei, Huifeng Xing, Hao Wang, Wanxin Shi, Sen Liu, Yang Xu 发表在 ICNL’ 2024上的工作。
本文发现基于参数服务器的 INA 方法在数学建模中缺乏增量部署能力,影响了数据中心的设计和升级。为此,提出了 Rina,首次在 Ring-Allreduce 架构中引入 INA 能力(每个 INA Switch 可以代替其 rack 下的所有 worker 加入环中,做到每加入一个 INA Switch 都能减少环长度),具备出色的增量部署能力,缓解了长依赖链问题。
Entry:Zotero link URL link
Motivation
- 目前的 AllReduce 通信方案存在问题:
- 基于 Parameter Server 的网内聚合的方法如 SwitchML、ATP、INAlloc 和 PANAMA 显著提高了网络拥堵和DDL效率,但可扩展性仍然很弱,需要更换拓扑中的几乎所有拥堵点交换机以实现网络吞吐量的显著提升。
- 基于 Ring-Allreduce 算法虽然避免了网络拥堵,但是因为依赖链过长,致系统吞吐量随着依赖链(环)的增长而下降。
- 因此 Rina 使用 INA 的方式,结合 Ring-Allreduce 算法实现具备可拓展性的 Allreduce 通信方案。
Design
建模含有 PS-based INA 的通信吞吐
- 定理如下:
- 对于仅包含常规交换机和 $n$ 个 worker 的拓扑结构,工作节点的吞吐量是 $1/n$
- INA Switch 及其子节点可以被看作是一个 worker
- 对于一个 INA Switch,实际吞吐量取决于表现 最差的子节点
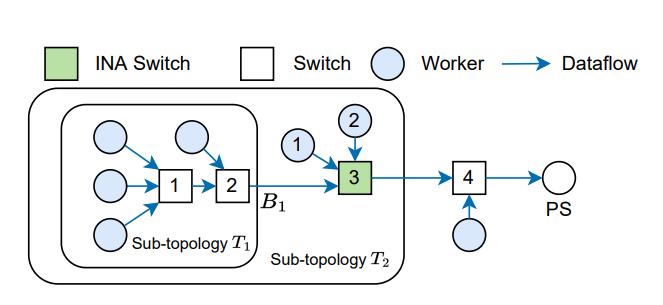
- 对于上图拓扑,首先分成仅有常规交换机和 worker 的 $T_1$ 应用定理 1,然后通过定理 3 求得 $T_2$ 的吞吐为 $B_1 = B_0/4$,通过定理 2 得到 Worker 4 下的两个链路最大吞吐可为 $B_0/2$,整个拓扑的吞吐受限于最慢的 $T_2$ 内的 $B_1$
Allreduce 过程
拆分成了 Scatter-Reduce 和 Allgather 过程,对于 Scatter-Reduce 过程:
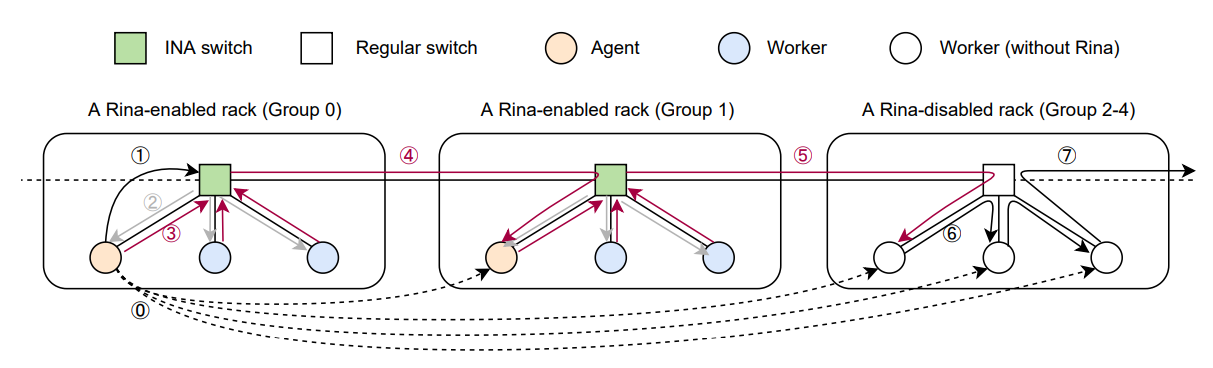
- 当 Agent(组内的唯一控制节点) 的当前计算回合完成时,它会将聚合任务数据传递给交换机 1️⃣。该信息包括下一小组的目标模型范围和大小、交换机中保留的内存空间以及当前参与聚合的 worker 的ID。
- 收到此数据后,交换机将此数据包转换为数据拉取消息2️⃣,并将其多播给此 rack 下的所有 worker(包括Agent)。
- 由拉取消息触发,所有节点开始向 ToR 交换机传输相应的梯度3️⃣。
- 这些参数随后在 ToR 交换机中进行聚合,并被发送到后续组的 Agent(4️⃣和5️⃣)。当下一小组的智能体收到来自(4️⃣和5️⃣)的聚合结果时,它会将这些结果与相应的本地梯度相结合。这些梯度部分随后在随后的阶段用于同步。
- 对于没有 Rina 的组,Rina 的同步机制仅需要对 Ring-Allreduce 进行微小的调整。对于 Group2-4,这部分通信退化为标准的RAR操作6️⃣。这保证了Rina 内部现有 Ring-Allreduce 的 最小更改,并支持与常规 Ring-Allreduce 的兼容性。
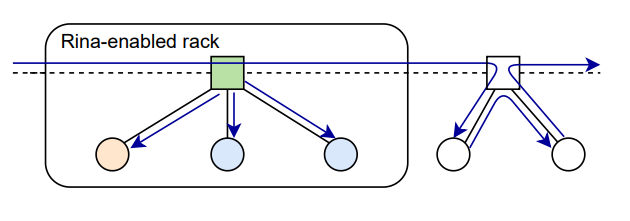
对于 AllGather 过程,主要使用多播进行加速:
其他设计拥塞控制和可靠保证
拥塞控制:由于 Rina 中 INA Switch 和 Woker 保持一跳的距离,因此拥塞控制方案比较简单。
可靠性保证:基于 P2P 的 Ring-Allreduce,无法遇到错误时主动排除节点,而对于 Rina-enabled rack 可以排除出故障的 Worker,如果 INA Switch 出错,可以切换成常规的 Ring-Allreduce
增量部署:为了减少 Ring-AllReduce 的环长,在初始部署阶段,替换过程优先将具有最多连接的普通交换机替换为INA交换机,在进行阶段,考虑通过最小生成树的构建方式进行逐步替换。
Evaluation
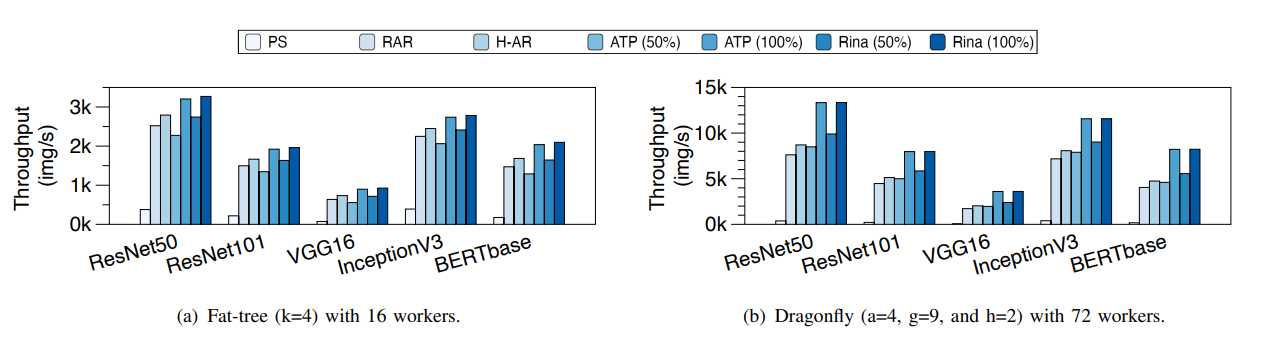
- Testbed Configuration: 两排,每排有4个节点。它们通过两个Intel Tofino-1 P4可编程交换机(具 有32x100Gbps端口)作为ToR交换机相互连接。每个节点配备一个AMD Epyc 7643 CPU(48核心,96线程), 128GB内存,以及一个带有2个100Gb端口的Mellanox ConnectX-6以太网网络适配器。此外,每个节点还配备一个NVIDIA RTX3090 GPU。使用脊叶拓扑结构
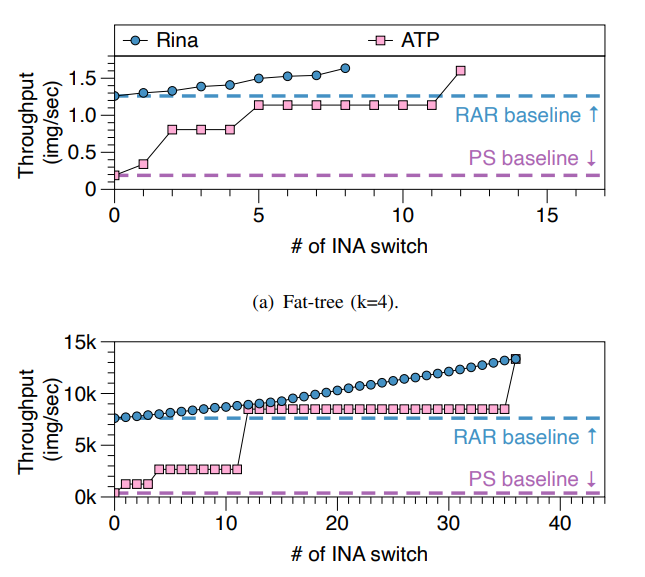
Conclusion
Pros:
- 不是对 GPU 通信进行设计的
- P4 交换机浮点数计算能力差,依赖量化行为,且无法支持大模型的 Reduce 过程
Cons:
- 设计简单,可兼容
- 数学形式讲清楚了Allreduce和PS-based INA的通信问题(尽管篇幅太长了)
Last modified on 2024-12-24