CodeCrunch: Improving Serverless Performance via Function Compression and Cost-Aware Warmup Location Optimization
该论文是来自Northeastern University的Rohan Basu Roy的工作,发表于ASPLOS ‘24上。
Abstract:Serverless computing has a critical problem of function cold starts. To minimize cold starts, state-of-the-art techniques predict function invocation times to warm them up. Warmedup functions occupy space in memory and incur a keep-alive cost, which can become exceedingly prohibitive under bursty load. To address this issue, we design CodeCrunch, which introduces the concept of serverless function compression and exploits server heterogeneity to make serverless computing more efficient, especially under high memory pressure.
Entry:Zotero link URL link
Motivation
- 冷启动时间长,目前的keep-alive方案存在两个问题:
- 由于内存有限,高峰负载期间,函数的温启动比例较低
- 现有策略没有考虑商用 ARM 和 x86 平台上提供的Tradeoff方案
- 观察1:
- 使用lz4压缩函数,使用10%的系统内存用于预热,静态10分钟的keep-alive策略
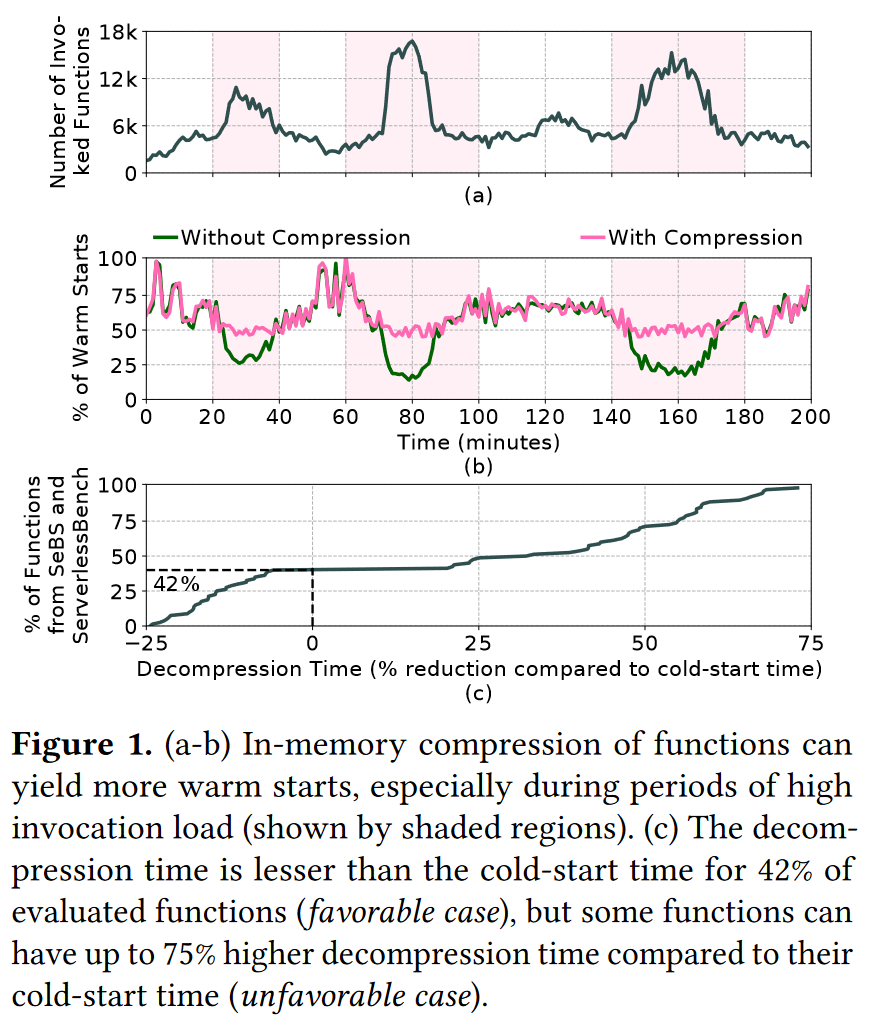
- 热启动的平均百分比从51%(无压缩)增加到61%(有压缩)
- 对42%的函数而言压缩-解压过程比直接冷启动好,平均好48%
- Challenge#1:确定压缩对哪些函数有利以及何时有利——这取决于在同一时间段内调用的函数和其他函数(一个复杂的优化问题)。
- 观察2:
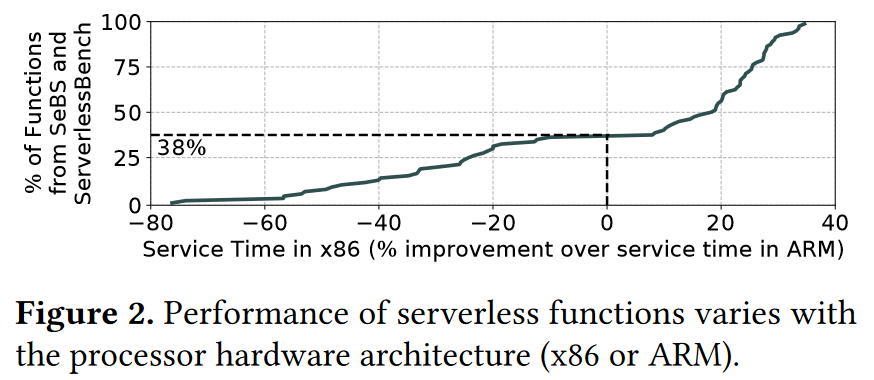
- Serverless平台提供异构,38%的函数使用ARM比使用x86更快,并且在ARM上keep-alive非常便宜
- ARM上46%使用压缩更好,函数中的38%ARM是性能更高的处理器选择,这38%的函数中有60%是ARM上的压缩功能。
- Challenge#2:确定在哪个处理器上预热哪些函数以及预热多长时间是一个复杂的优化问题
- 观察3:
- 优化参数:
- 以最佳方式决定函数调用后keep-alive的时间
- 决定在keep-alive期间在内存中压缩哪些函数以及何时压缩哪些函数
- 智能地利用带有x86和ARM处理器的服务器来提高性能和保持活动成本
- 需要调参的空间大,传统方式无法解决
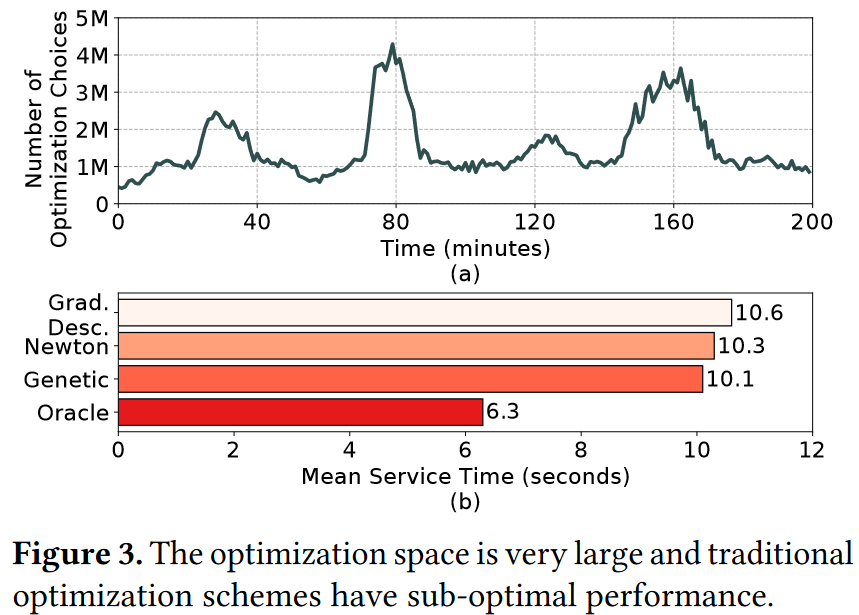
- 优化参数:
该技术旨在通过优化函数保持活跃时长、选择合适的压缩策略,以及利用异构处理器的性能特点,来提高serverless计算的整体性能和效率。
Design
- 主要基于SRE(Sequential Random Embedding)顺序随机嵌入设计决策流程:
- 第一步:
- 使用优化空间生成器:每分钟为这短时间调用的所有函数生成压缩选择(基于当前剩下的Keep-alive预算)
- 约束条件:
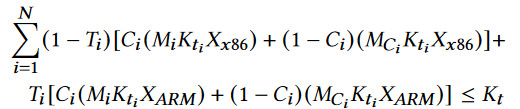
- $M_i, M_{C_i}$ 压缩或者不压缩的内存占用,$X_{x86}, X_{ARM}$ keep-alive的成本,$K_{t_i}$ keep-alive次数,$K_t$ 总keep-alive的预算
- 采样:记录本地和全局调用周期的平均值和标准偏差local指的是最近的𝑛𝑙调用,而global指的是函数的所有调用
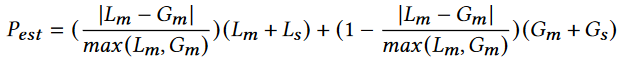
- 第二步:使用SRE进行优化:在每个优化轮次,随机选择一个小规模的子集函数进行优化。
- 对于子集,采用梯度下降法,以子问题中函数的估计平均服务时间最小的方向每轮进行一步优化,找到局部最优的C K X类型组合。
- 将这些最优组合应用到子集中的函数上,并更新整体的预算和性能指标。
Question
- 冷启动和Keep-Alive谁更贵
- 有些函数的调用模式在某种程度上是周期性的,但是多个周期频率和频繁变化的调用模式(包括变化周期)的存在会使它们的调用周期难以预测。它们的输入经常发生变化,从而导致它们的执行时间和调用频率发生变化。这就是为什么像SRE这样的随机算法在无服务器设置中是有益的,因为生成的解决方案不太依赖于函数的单个特征,并且可以通过随机重新选择函数以在不同的时间间隔创建子问题来捕获执行时间和调用模式的变化。
Last modified on 2024-07-11