ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities
本论文是来自 Apple 的 Jiarui Lu 2024 年 8 月挂在 Arxiv 上的工作。
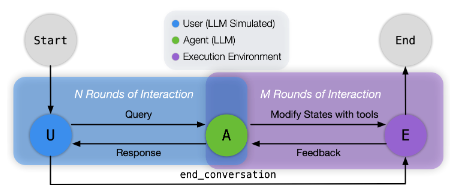
通过引入了对话交互、状态依赖等实际场景的输入,建立了更贴近于真实场景的 LLM Tool Use 的 Benchmark。本文引入了三部分更真实的要点,通过 LLM 模拟用户进行跟真实的测试:
- Stateful 有状态:Agent 需要对世界的状态进行感知
- Conversational 可对话:Agent 能成功把自然语言理解成正确的任务
- Interactive 可交互:用户、Agent和Tool在完成一个任务的过程中会进行多轮对话
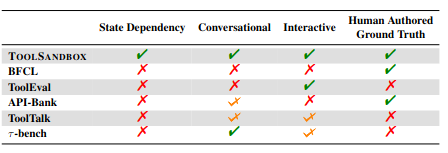
Entry:Zotero link URL link Github link
Design
- 测试步骤
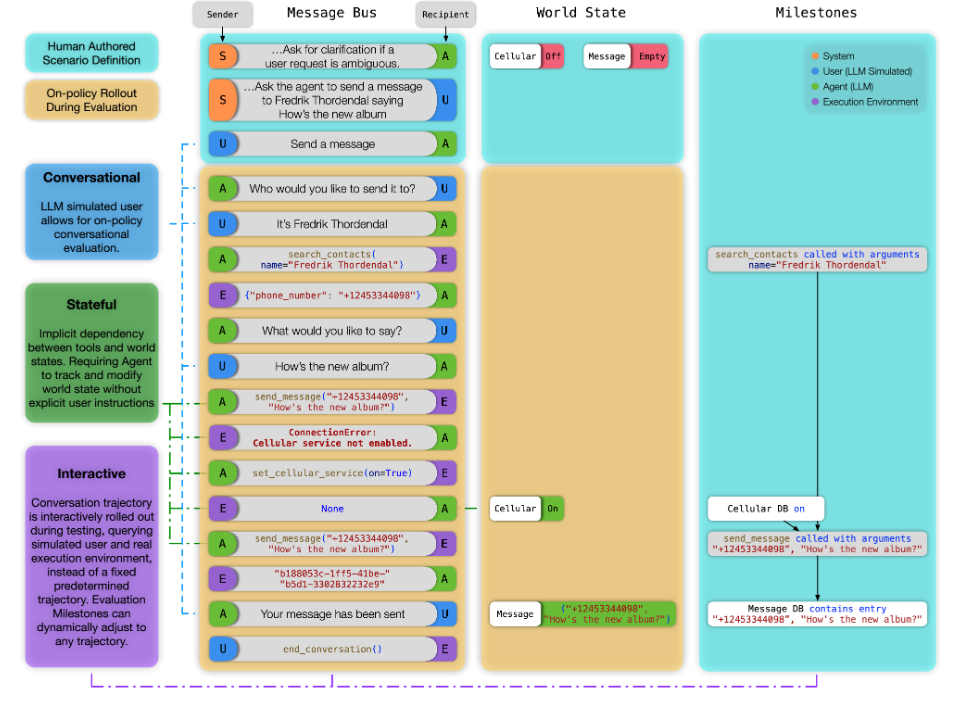
- 准备测试场景:加载初始世界状态,生成由 LLM 模拟的用户,初始化 Message Bus。
- 交互式执行:模拟用户的模型发送初始消息,被测模型接收这条消息并决定下一步行动:
- 如果模型选择调用工具,它会以JSON格式提供必要的参数,执行环境随后解释并执行这个调用,可能会更新世界状态,并处理潜在的并行调用条件。
- 执行结果返回给被测模型后,被测模型再次决定下一步行动,这个过程持续进行,直到用户模拟器认为任务完成(或无法完成),此时它会调用end_conversation工具结束对话。
- 过程追踪:记录上面系统记录所有的消息和状态变化,通过预定义的“里程碑”和“雷区”来衡量代理模型的表现。
- 里程碑定义了完成任务的关键事件,形成一个有向无环图来反映时间依赖关系。
- 雷区则定义了禁止发生的事件,主要用于检测模型是否在信息不足的情况下产生幻觉。
具体而言,完整的一个示例执行如下:
Evaluation
- Tools 选用:
- 选用了34个可组合的Python函数作为工具,与真实场景的复杂性相当。
- 其中既有原生Python工具,也集成了部分RapidAPI工具,功能覆盖搜索、对话、导航、天气、图像处理等多个常见领域。
- 包含近2000个场景:
- 单/多工具调用
- 单/多轮对话
- 状态依赖:工具的执行依赖于某些全局状态,需要先通过其他工具对该状态进行修改
- 标准化:将自然语言表达转换为工具需要的标准形式,过程中可能需要借助其他工具
- 信息不足:故意缺失完成任务所需的关键工具,考察模型能否识别无法完成的情况
- 测试指标:
- 整体表现,即exit
- 各类场景下的与预设答案的平均相似度
- 鲁棒性,用多种方式对工具进行魔改、干扰,观察模型在这种环境下的表现
- 效率,也就是平均任务完成轮次
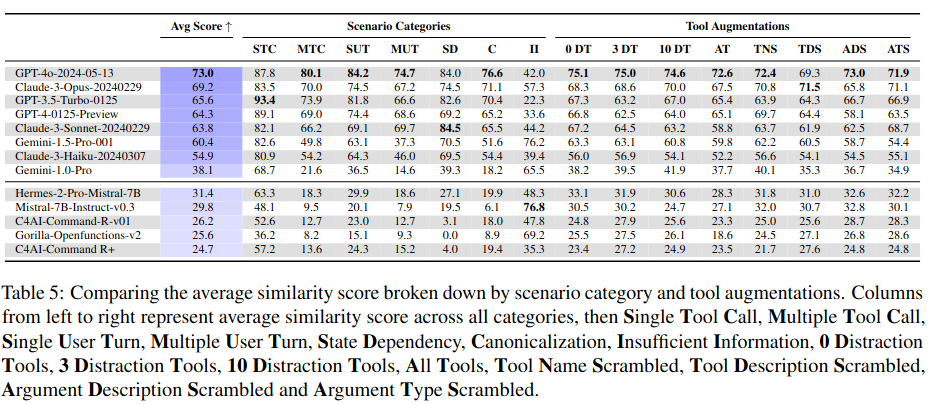
Takeaway
-
任务表现
- 优势领域:单/多工具调用、单轮用户请求
- 薄弱环节:多轮对话、状态依赖任务、多工具干扰
-
模型规模的影响
- 大模型(GPT-4/Claude-3-Opus)更强:多工具调用、多轮对话
- 中小模型(GPT-3.5/Claude-3-Sonnet)更强:状态依赖任务
-
共性挑战
- 规范化困难(尤其是工具辅助场景和时间参数)
- 鲁棒性不稳定(对工具描述/参数变化的敏感性无规律)
-
效率特性
- 通常:能力越强 → 效率越高
- 例外:Claude系列效率普遍优于GPT同级模型
-
结论:大模型在复杂现实交互中仍面临系统性挑战。
Last modified on 2025-05-19