本文是来自MIT的Vaishaal Shankar, Karl Krauth, Kailas Vodrahalli, Qifan Pu, Benjamin Recht, Ion Stoica, Jonathan Ragan-Kelley, Eric Jonas, Shivaram Venkataraman等人发表于SoCC‘ 20的工作。
Abstract: Datacenter disaggregation provides numerous benefits to both the datacenter operator and the application designer. However switching from the server-centric model to a disaggregated model requires developing new programming abstractions that can achieve high performance while benefiting from the greater elasticity. To explore the limits of datacenter disaggregation, we study an application area that near-maximally benefits from current server-centric datacenters: dense linear algebra. We build NumPyWren, a system for linear algebra built on a disaggregated serverless programming model, and LAmbdaPACK, a companion domain-specific language designed for serverless execution of highly parallel linear algebra algorithms. We show that, for a number of linear algebra algorithms such as matrix multiply, singular value decomposition, Cholesky decomposition, and QR decomposition, NumPyWren’s performance (completion time) is within a factor of 2 of optimized server-centric MPI implementations, and has up to 15% greater compute efficiency (total CPU-hours), while providing fault tolerance.
Entry:Zotero link URL link
Numpywren(SoCC 20')
- 资源解耦带来了机遇和挑战:
- 机遇:可以运行时按需申请和取消资源,提供更高的资源利用率和更低花费;
- 挑战:MPI,MapReduce等范式高度依赖整合资源,不适应资源解耦
- 现有FaaS的不足:
- 函数分割要求无状态,需要编程人员改变书写的方式
- 也因为对无状态的强要求,传统优化方式如数据本地性和分层通信不可实现
- 内容:
- 在资源解耦的场景,达到基于MPI的分布式程序的时延,并减少资源整体使用量。
- 设计一套语言(lambdapack),支持表示线性代数的FaaS细粒度切分和资源解耦的编程(核心思路:将S3视为内存,本地内存视为寄存器)
- 设计一套框架(Numpywren),支持分析lambdapack的依赖并建立并行计算的task(解析Compressed DAG进行并行化分解),执行运算和错误恢复
- 结论:
- 在延迟略微变慢($\le 60%$)的情况下,提升了利用率($15%$)
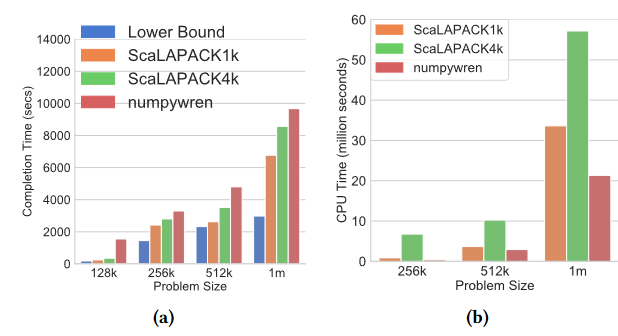
- 在延迟略微变慢($\le 60%$)的情况下,提升了利用率($15%$)
- 不足
- 没有给出MPI实现的通信,很有可能是s3通信方式比MPI原始的更强(numpypywren会导致$21\times$的通信量,却在通信开销上只慢了$47%$ ,很有可能是这一点导致的)
- 需要预编译进行转成lambdapack,要求索引都是常量才能解析数据依赖,不能替代MPI等范式
- 只适合稀疏矩阵计算
Last modified on 2023-07-22