本论文是Guanhua Wang, Heyang Qin, Sam Ade Jacobs, Connor Holmes, Samyam Rajbhandari, Olatunji Ruwase, Feng Yan, Lei Yang, Yuxiong He发表在 ICML'24上的工作。
本工作主要通过量化和分级通信,分别优化了训练中 ZeRO3 中的三种不同集合通信过程,使跨节点通信的总量从 3M 降低到 0.75M.
Entry:Zotero link URL link
Motivation
ZeRO 尽管能够高效的训练大规模模型,然而其在某些场景下依然面临着性能不高效的问题:
- cluster with low bandwidth:如今的硬件在 intra-node 和 inter-node 的 bandwidth 相差巨大,因此,对于具有较多通信的训练场景下,跨节点通信很容易成为训练瓶颈
- very small batch sizes per GPU:当 global batch size 保持不变时,随着 GPU cluster 的规模增大,每个 GPU 能够处理的 batch size 会逐渐减少。而这会使得通信和计算的比例逐渐增大,从而造成通信瓶颈
在 ZeRO3 的过程中,一次forward+backward迭代需要进行三次集合通信:
- all-gather paramters in forward
- all-gather parameters in backward
- reduce-scatter gradients in backward
因此文章提出ZeRO++进一步减少这些通信的通信量,主要包括:
- Quantized Weight Communication for ZeRO(qwZ):在forward做weight all-gather时,将weight进行量化以此来减少通信量
- Hierarchical Partitioning for ZeRO(hpZ):在backward做weight all-gather时,将weight的切分限制在sub-group中(一般为节点内),从而减少节点间的通信
- Quantized Gradients Communication for ZeRO(qgZ):在做gradients reduce-scatter时,将gradients进行量化以此来减少通信量
Design
Quantized Weight Communication for ZeRO
使用分组量化策略,对于一个 weight 矩阵通过按行/列分组量化的形式,减少量化误差
在前向传播做weight all-gather之前,将 weight 从 fp16 量化为 int8 类型,做完 all-gather 通信后,又将 weight 从 int8 还原为 fp16 类型
Hierarchical Partitioning for ZeRO
在ZeRO中,参数的切分发生在所有的 GPU 之间,即被切分成 world size 份,那么这些参数所涉及到通信自然也在所有 GPU 之间发生。hpZ 则主要优化的是反向传播中的 all-gather 通信,通过将参数切分限制在 secondary-group 内,通常而言是限制在单个节点内,节点之间的参数则是 replica,通过牺牲显存的方式来避免在所有 GPU 之间做通信,从而提升通信效率。
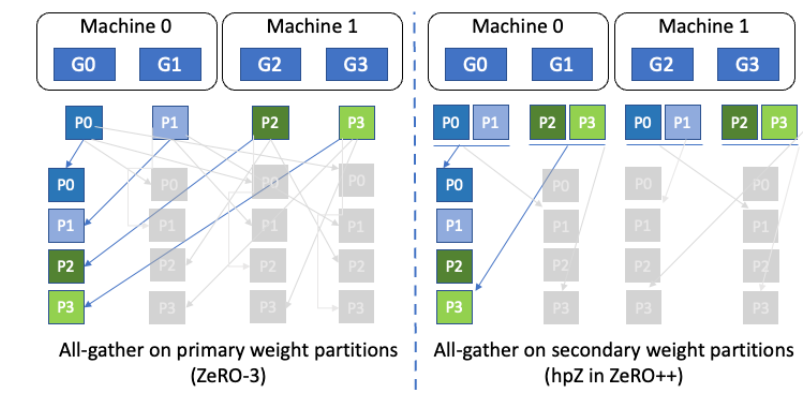
如图所示,在ZeRO3中,paramter 被切分成4份,每个 GPU 拥有一份,自然 parameter 的通信发生在四个 GPU 之间(这里会涉及到跨节点通信);在 hpZ 中,paramter 被切分成两份,G0 和 G2 拥有的 paramter 是相同的,这样 paramter 的通信只会发生在节点内,而这需要更大的显存来确保 GPU 能够放下 paramter 的切片。
一次iteration过程:
- weight在primary group(指所有的gpu)内被切分
- all-gather weight in primary group before forward
- forward
- partition weight in secondary group
- all-gather weight in secondary group
- backward
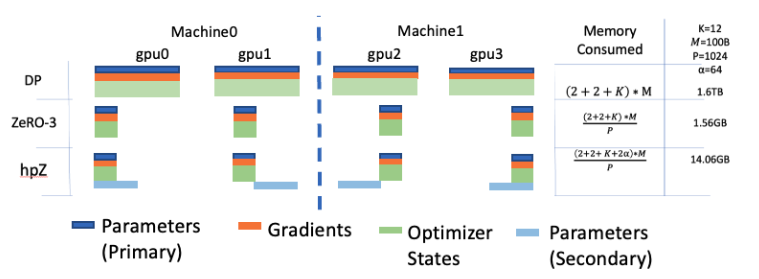
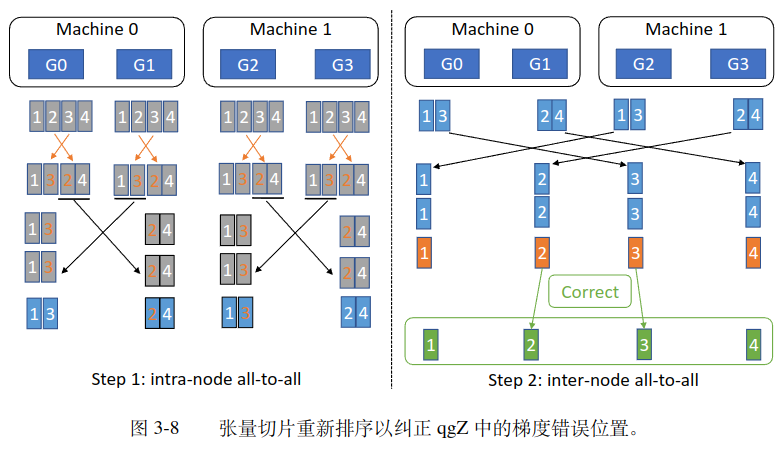
Quantized Gradients Communication for ZeRO
做 reduce-scatter 之前将 gradients 从 fp16 转化为 int4 类型,做完r educe-scatter 通信后,将 gradients 从 int4 类型还原为 fp16 类型
为了实现这一目标,主要做了三件事情:
- 使用 all2all 通信代替 reduce-scatter 来减少量化误差和量化时间
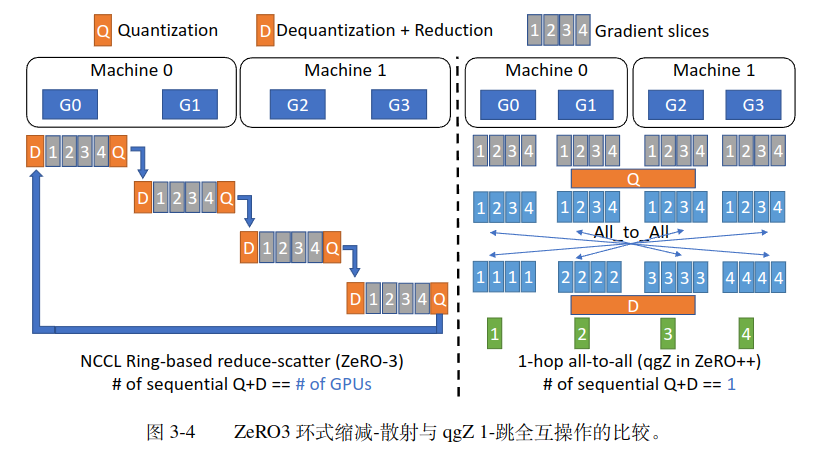
- 设计了分级的 all2all 通信来进减少节点间通信量
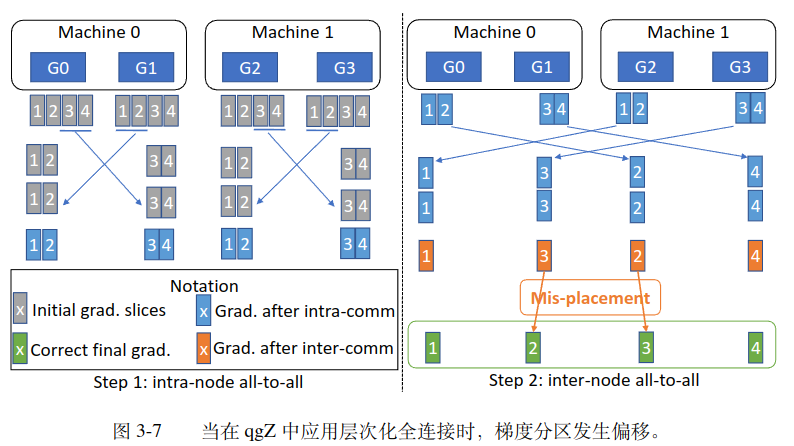
- 使用 tensor slice reordering 算法来保证通信结果的正确性
Implement
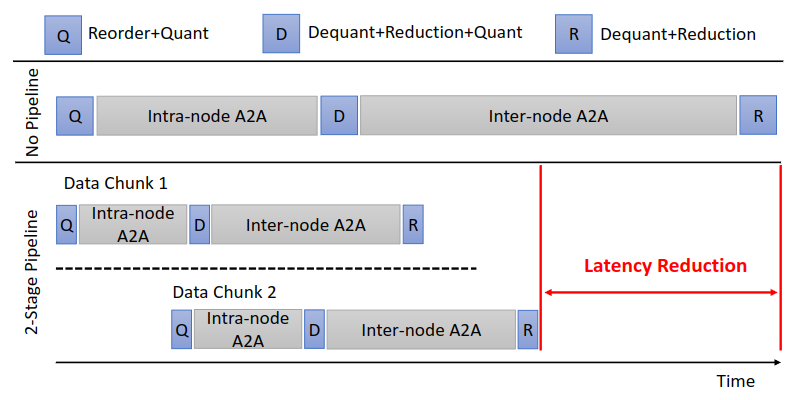
实现过程中,通过把数据切成多个 data chunk,可以进行 intra-node 和 inter-node 通信的 overlap:
Last modified on 2024-11-13